流水线理解笔记
由于在做组成原理实验的时候,碰到了流水线这个概念,感觉什么都不懂,所以从头开始做做试验来理解一下这个概念,其中的Demo来自于重庆大学组成原理实验指导书Lab1,它的作者是
lvyufeng@cqu.edu.cn
我在作者提供的代码、描述的基础上进行了仿真实验,结合个人理解写下了这篇博客,这个博客以实验、代码为基础,根据行为仿真结果来进行讨论。
错误说明
在最终的实现中,rst与流水线的刷新不应融合到一起,流水线的刷新应当用于流水线的部分刷新,而rst应该用于整体刷新。
vivado 有相应的免费版本,官网提供免费下载。
环境
顺便吐槽一下这个HEXO,我用typora编辑出来的代码,他给我隔一行隔一行的放,我用makrtext编辑的代码他直接给我搞成一行了,这咋办呢?
使用的环境是Vivado 2019.1 ,如果你也想用这个环境的话,你可以:
去官网买正版(绝对支持)
去网上搜索一波
去淘宝花30买个
简单流水线
先从一个简单的、没有阻塞的流水线开始。
在开始之前,给大家几点建议(个人看法):
装个文本编辑器吧:vivado自带的文本编辑器太难用了, 建议装一个VSC或者sublime。
去复习一下VHDL的基础,熟悉一下什么叫阻塞赋值什么叫非阻塞赋值,以及一些类型之间的区别
下面先看代码:
1 |
|
仿真代码:
1 |
|
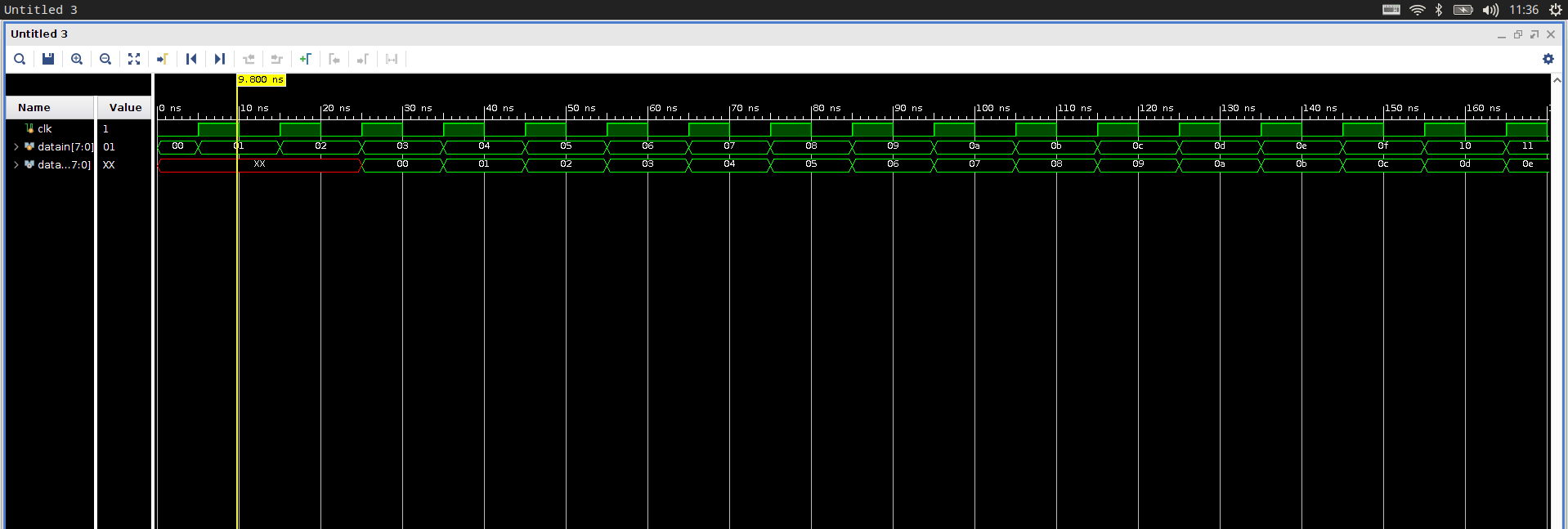
仿真波形图:
代码
这个基础的流水线非常好理解,就是数据传入后,每次检测到时钟上升沿,就将数据进行一次平移,如下图所示:
graph LR datain -- posedge clk--> piprData1 piprData1 -->|posedge clk| piprData2 piprData2 -->|posedge clk| piprData3 piprData3 --> dataout
可以看到在这个过程中,前三次都需要在检测到时钟上升沿的时候才能够进行非阻塞赋值,而最后一次是连续赋值。
要想理解这个过程,需要明晰一些概念:
连续赋值:带有assign的是连续赋值,如上方代码中的
assign dataout = piprData3;连续赋值中赋值符号左方的变量必须是线网类型,这步操作,从硬件的角度理解就是将赋值符号右边与左边进行连线,当右边发生变化的时候,左边立刻发生变化。非阻塞赋值与阻塞赋值:
阻塞赋值:
[变量] = [逻辑表达式];非阻塞赋值:
[变量] <= [逻辑表达式];阻塞赋值和非阻塞赋值之间的区别主要在于
阻塞,所谓阻塞,阻塞的是当前其他的赋值任务,其中:阻塞赋值,阻塞了其他的赋值任务,所以表现出的效果就和C中的赋值语句非常相似
非阻塞赋值,没有阻塞其他的赋值任务,所有的赋值都是并行的,想要理解这个,你需要先明确一件事情:用Verilog写代码写出来的是个电路,而非软件。
有阻塞的三级流水
代码:
1 |
|
仿真
1 |
|
波形图‘

这个代码看似非常复杂,实际上还是很简实际上还是很简单的,每一层的逻辑都是相似的,每一层与上一层的数据转移是有三个变量进行控制的:
pipeXReadyGo:表示当前层的数据能否进入下一层
pipeXAllowIn:表示当前层能否接受上一层的数据
pipeXToPipeX+1Valid:表示在本时钟周期内,是否会进行传输
我们设计的逻辑如下:
当前层能否进入下一层:始终可以
当前层能否接受:当前层值无效或当前层可以进入下一层,并且下一层可以接收
本次能否转移:本层值有效,并且可以传入下一层
由于我们这样的设计思路,并且allowIn,validOut始终为1,所以我们达到的效果与第一次相同。
简单流水线加法器(8bits 2级流水)
1 |
|
这个比较好懂,我就不做过多说明了,但是我想着重讲的是:为什么流水线比普通的看?我们从RTL电路上来看:


上面的是普通的加法器,下面的是流水线加法器,可以看到,对比两者,流水线加法器所使用的寄存器较多。
再看运算速度,对于上面的普通加法器,完成sum1需要等待8个周期,完成sum1后再进行sum0,又需要八个周期,这样就需要16个周期。而对于下面的流水线来说:前四位和后四位的加法同时进行,消耗四个时钟周期,完成后,进行进位,消耗4个周期。所以说,使用流水线可以加快运算。
8Bit 4级流水——无阻塞简单版
一共有四层,所以叫四级流水:
1 |
|
生成的RTL电路图如下:

仿真:
1 |
|
波形图:

只用了四个周期就算出来了。
8Bit 4级流水——带有暂停刷新功能
在做它之前,我们先来讨论一个问题:为什么需要暂停刷新功能?这是因为不同的指令需要不同的周期,在执行多周期指令的时候,如果cpu不支持动态指令调度和多发射,那么必须停顿。
1 |
|
仿真
1 |
|
仿真波形图:
30ns时,rst = 1,60ns时,重新将rst置为0,并且,每10ns翻转一次stop
 在90ns的时候将rst置为1,并在120ns时,将其置为0,则仿真波形图如下:
在90ns的时候将rst置为1,并在120ns时,将其置为0,则仿真波形图如下:

validOut正确,如果大家觉得这段结果难以理解,那不是因为你们菜,而是因为我这个测试用例设计的太狗屎了。
下面取消对rst的更改,全程不刷新,只进行周期性stop:

最后,不stop,也不刷新:

算了,再加最后一组,只刷新,不stop:

在最后一组中,可以看出:当刷新被重置为0时,开始重新计算,4个时钟周期后,计算完成,validOut被重新置为1。如果大家还是看不懂,可以copy下来代码,自己跑跑试试,我这个用例造的着实垃圾。