组成原理(三)下——浮点数运算
浮点数的表示
基础原理
有很多数字非常的大或者非常的小,会超出32位2进制数的表示范围。所以仅使用整形变量或是定点数并不能满足我们的需求,所以我们有了一套由十进制的科学计数法推广而来的浮点数表示方法。首先,我们来回顾一下十进制下的科学计数法: \[ N = 10^E *M \] 我们把它推广到R进制,就可以得到: \[ N = R^e*M \] 我们给他们都来命一个名:
- R:基数,对于二进计数值的机器是一个常数,一般规定为2、8、16中的一个
- e:指数
- M:尾数
一个机器浮点数由阶码和尾数以及符号位组成:

- 尾数:用定点小数表示,给出有效数字的位数
- 阶码:用定点整数形式表示,知名小数点在数据中的位置,决定了浮点数的表示范围。
通俗的说,就是:阶码控制一个范围\([-X,X]\)我们可以将这个范围看作一个区间,然后尾数,也就是这个定点小数表示当前的数字在这个区间中的相对位置。
IEEE754(重点)
标准表示方法:为便于软件移植,使用 IEEE标准IEEE754 :(重点)
- 尾数用原码;
- 阶码用变形移码;
- 基为2
按照该标准,32位浮点数和64位浮点数的标准格式为:
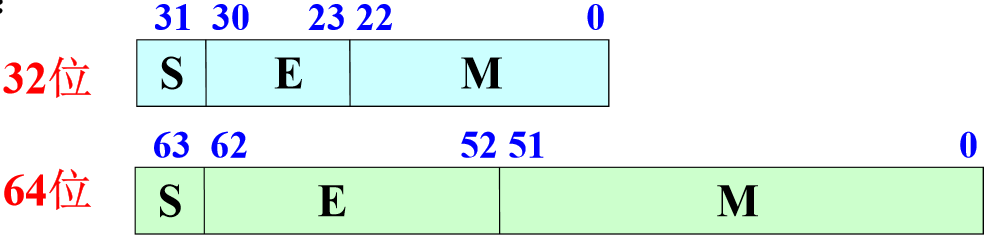
其中:
- S—尾数符号,0正1负
- M—尾数,纯小数表示,小数点放在尾数域的最前面,采用源码表示
- E—阶码,采用移码表示(后面填坑)
浮点数的规格化表示
众所周知,一个数可以由很多种科学计数法来表示,比如:
\(0.5 = 5*10^{-1}=0.5*10^{0},....\)
我们可以一直写下去,那显然,如果大家都乱写就乱套了,所以为了提高数据的表示精度,需要做规格化处理,这样做可以:
- 提高表示精度
- 使数据表示有唯一性
Q:什么是规格化?
A:如果尾数为R进制的规格化,绝对值大于或等于\(\frac{1}{R}\)
二进制源码的规格化数的表现形式:
正数:\(0.1....\)
负数:\(1.1....\)
补码位数的规格化的表现形式:
正数:\(0.1....\)
负数:\(1.0.....\)
补码下尾数的最高位域符号位相反
可能有人看到这里看不懂,我解释一下,规格化处理后的数字应该满足尾数的绝对值大于或等于\(\frac{1}{R}\)这里有\(R=1\),所以我们规格化处理后,尾数的绝对值应当大于等于0.5,0.5是什么?是2的-1次方,那么二进制源码表示下当尾数的最高位为1时,就满足规格化,这样的设计便于判断。
为什么这样的设计能够提高精度?
要想知道为什么这样做能够提高精度,就应当先了解为什么会产生精度误差。产生精度误差的原因是:当我们要表示的数很小或不能被准确表示的时候,我们的区间长*比例只能达到近似解。那么我们分析以下两种情况:
- 例子:表示0.0001
- 大区间小比例:
- 假设我们的指数为表示出来的值为100,那么我们想要表示0.0001,就需要让尾数位为:0.000001,但是众所周知,二进制数在很多情况下都只能尽量地逼近这个数,那么问题来了:该怎么让尾数尽可能地逼近这个数呢?答案就是:尽量用更多的位。那么反过来观察我们的方法,我们浪费了尾数位的高位。这显然是不理智的。
- 小区间大比例:
- 我们刚才悟出了一个道理:精度主要由尾数位的准确程度决定,那么我们就要尽量的压榨尾数位,什么时候才能把它压榨到极限呢?答案很简单:第一位不为0。
隐藏位计数
我们还可以再使用隐藏位技术再提高一点精度,既然我们都知道,尾数的第一位必为1了,那我们还记录他干什么呢?那么我们在记录尾数的时候,可以将尾数的最高位通过左移一位隐藏起来(其实就是自然溢出),这样就可以再多记一位尾数了。
规格化浮点数的真值
我们通过32位浮点数来看:
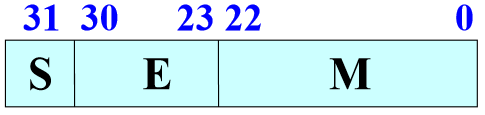
移码定义: \[ \begin{align} \begin{array} x[x]_移 &= x_0x_1x_2x_3...x_n\\ & = 2^n +x \end{array} \end{align} \] 实际上就是:在\(2^n\)的基础上进行平移。
一个规格化的32位浮点数的x的真值为: \[ x = (-1)^s*(1.M) * 2^{E-127} \] 一个规格化的64位浮点数x的真值为: \[ x = (-1)^s*(1.M)*2^{E-1023} \]
例题1
若浮点数x的二进制储存格式为:\((41360000)_{16}\)求其32位浮点数的十进制格式:

例题2
将十进制数20.59375转换成32位浮点数的二进制格式来存储。
首先先将整数部分和分数部分转化成二进制数:
\(20.59375 = 10100.10011\)
移动小数点,使其在1,2位之间:
\(10100.10011 = 1.010010011 * 2^4,e=4\)
得到:\(e = E - 127\)
\(S = 0, E = 4+127=131=1000,0011,M = 010010011\)
最后得到32位浮点数的二进制储存格式为:
\(0100,0001,1010,0100,1100,0000,0000,0000\)
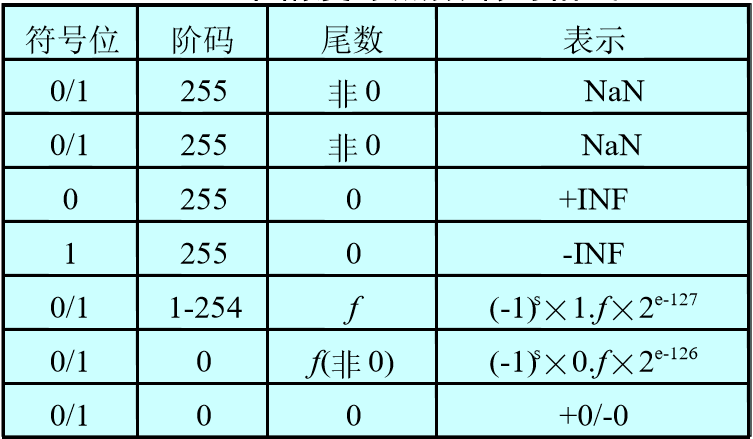
IEEE754浮点数的范围

浮点数的加减
加法
我们先从算数式的角度去理解,假设我们已经有了两个浮点数,它们分别是:
\(x = 2^{Ex}M_x\)
\(y = 2^{Ey}M_y\)
其中,E代表阶码,M代表尾数
那么两个浮点数进行加减运算实际上就是: \[ x \pm y = (M_x2^{Ex-Ey} \pm M_y)2^{Ey},E_x \leq E_y \] 说白了就是分为几步:
- 一、将两个数对齐,对齐到阶码大的数那里
- 二、将对齐后的尾数相加
- 三、乘上较大的阶码表示的数
那么我们将这个操作转化到机器上,就变成了:
一、0操作数的检查:
二、比较阶码大小并完成对阶(小的数向大的数对齐),小阶的尾数右移,每右移一位,其阶码加1(右规)。
三、尾数进行加或减运算
四、结果规格化:尾数运算完之后可能不满足规格化的要求,所以要进行规格化处理
- 向左规格化:如果不是规格化的数,需要尾数向左移位,这个很好理解,就是太小了需要大一点,实现方法就是:每向左一位,阶码减1,直到满足规格化要求为止
- 向右规格化:两个满足规格化的数相加,可能太大。所以需要用右移的方法使结果满足规格化要求。方法是:每右移一位,阶码加一,直到满足规格化要求为止。
五、舍入处理:在对阶或向右规格化的时候,尾数要向右进位,这样被右移的尾数的低位部分会被丢掉,从而会造成一定的误差,所以要进行舍入处理。
- 0舍入1法:
- 如果右移的时候被丢掉的位数的最高位为0就舍去,否则就加一
- 恒置1法:
- 只要数位被移掉,就在尾数的末尾置1。
- 0舍入1法:
六、溢出处理:将数字右规后,再根据阶码来判断浮点运算是否溢出,溢出可以分为三类:
- 负上溢:
- 正上溢:正负上溢都一样,就是+1操作的时候,没法再加了,就溢出了
- 下溢:向左规格化的时候,阶码已经小于0了,但是仍然要减1,这时叫做下溢
所以我们说,浮点数的溢出是以其阶码溢出表现出来的:
- 阶码下溢是由于表示的数的绝对值太小了,这时可以把数看作0
- 阶码上溢是由于表示的数的绝对值实在是太大了,可以把数看作无穷
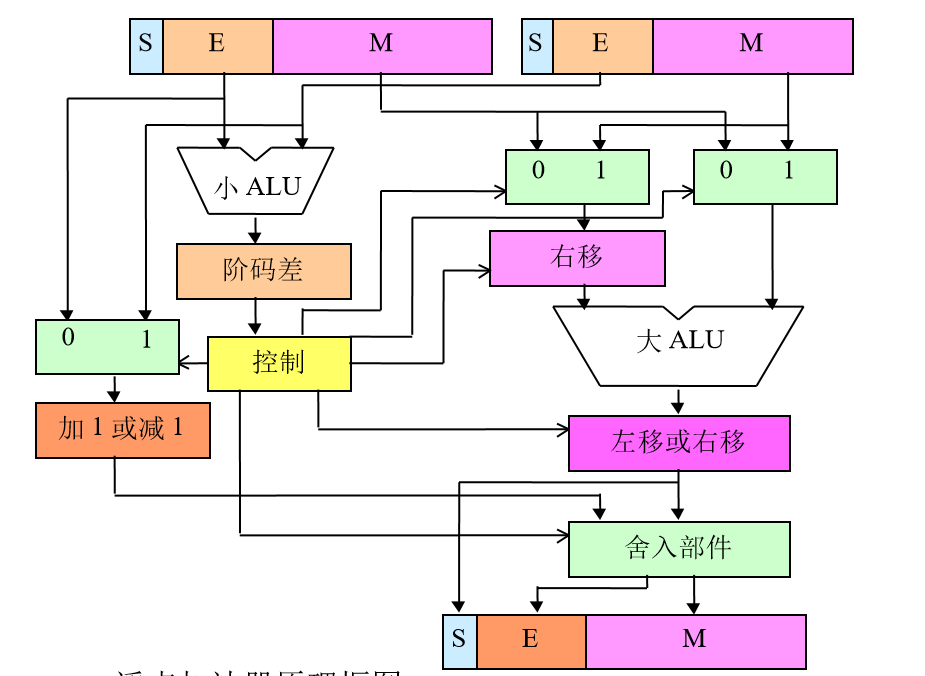
流程图就直接copy老师的了:
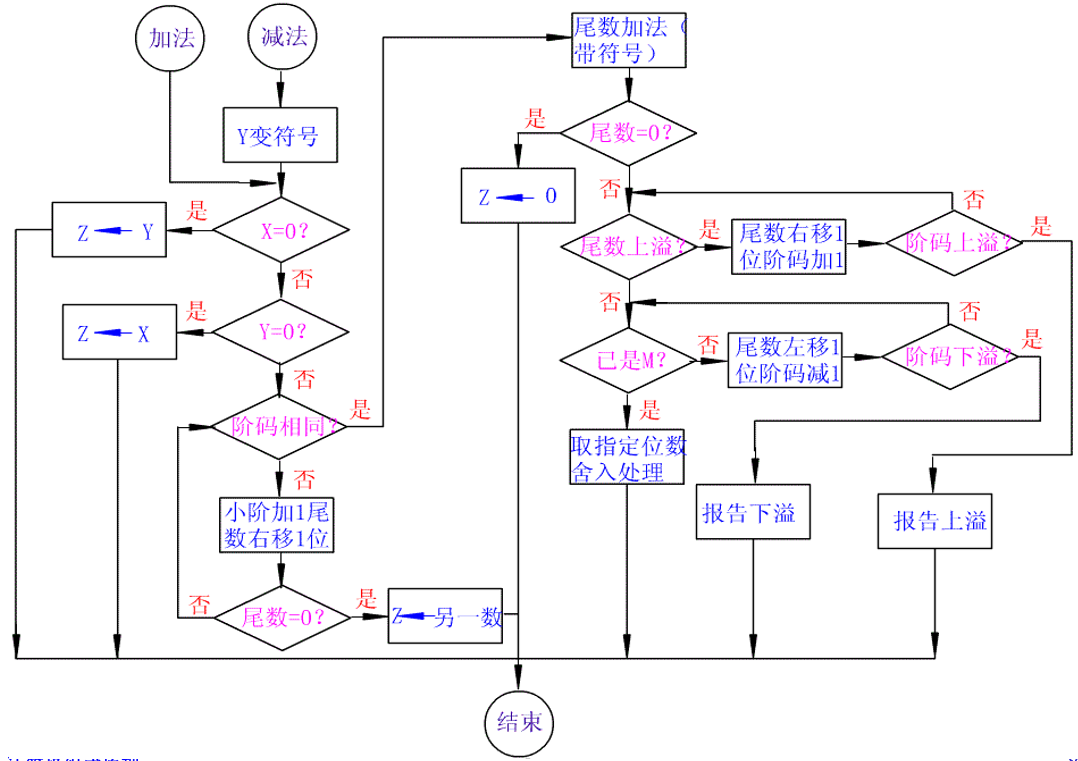
例题

硬件电路
浮点数的乘除运算
\(x = 2^{Ex}M_x\)
\(y = 2^{Ey}M_y\)
乘法运算规则: \[ x*y = 2^{(E_x+E_y)}*(M_x*M_y) \] 除法规则: \[ x \div y= 2^{(E_x-E_y)}*(M_x \div M_y) \]
移码的溢出判断
首先明确:使用双符号位的阶码加法器,规定移码的第二位始终为0,那么移码的第二位为1的话就说明他溢出了。
- 当低位符号为0时,(10)表明结果上溢
- 当低位符号位1时,(11)表明结果下溢
- 最高位为0,说明没溢出
- 低位符号为1,(01)结果为正
- 低位结果为0,(00)结果为负
尾数处理
浮点加减法对结果的规格化及舍入处理也适用于浮点乘除法。
例题

浮点数表示和算法总结
- IEEE754
- 尾数规格化
- 浮点数计算流程
- 浮点数计算硬件实现
MIPS中的浮点数指令
在mips中有32个单精度的寄存器,专门用于浮点数的操作。记作:\(f_0,f_1,...,f_{31}\),在储存单精度浮点数的时候,我32个可以分别使用,而在储存双精度浮点数的时候可以两两组合使用,也就是\(f_0/f_1,f_2/f_3,...,f_{30}/f_{31}\)。
单精度的加减乘除指令:
1 | add.s, sub.s, mul.s, div.s |
双精度的加减乘除:
1 | add.d, sub.d, mul.d, div.d |
值得注意的是,上面说过双精度浮点数储存在两个连续的寄存器中,我们一般用开头的那个寄存器来代指另这两个寄存器的总体,所以我们上面的加法\(f4 = f4 + f6\)中的f4实际上是指的f4f5连接而成的双精度数,当然f6也是同理。
例题1
1 | float f2c (float fahr){ |
MIPS:
1 | f2c : lwc1 $f16, const5($gp)# 从环境中把5读入 |
例题2
1 | void mm(double x[][], double y[][], double z[][]){ |
假设x,y,z分别在$a0, $a1, $a2,并且i,j,k在$s0,$s1,$s2。
MIPS:
1 | li $t1, 32 # t1 = 32,用于判断是否临界 |
精度误差
GRS
双精度的尾数只有53位,即使包含了一个恒为1的隐藏位。但是他只能表述\(2^{53}\)个数字,所以她表示的过程中一定是有一定的精度误差的,为了保证精度,IEEE754定义了一些额外的规则,比如这里的GRS。其中guard、round、sticky是53位以外有额外增加的三位。
- guard,保护位
- round, 舍入位
- sticky,黏贴位
\[ F = 1.xxxxxxxxxxxxxxxxxxx\ G \ R \ S \]
但是不是所有的处理器都实现了这样的操作,这是因为我们需要在硬件实现的成本、效率、市场等角度去做均衡。实际操作过程中,根据IEEE754,中间结果在右边至少应该增加两个附加位(guard & round):
- Guard bit(保护位):在尾数部分右边的位
- Rounding bit(舍入位):在保护位右边的位
附加位的作用:用于保护对阶时向右移的位或运算的中间结果
附加位的处理:
- 左规的时候被移动到尾数中
- 作为舍入的依据
舍入方式
- 一、就近舍入:舍入为最近可表示的数
- 二、朝正无穷舍入:舍入为Z2(正向)
- 三、朝负无穷舍入:舍入为Z1(负向舍入)
- 四、朝0方向舍入:截去,正数:Z1;负数:取Z2;
由计算顺序引起的误差
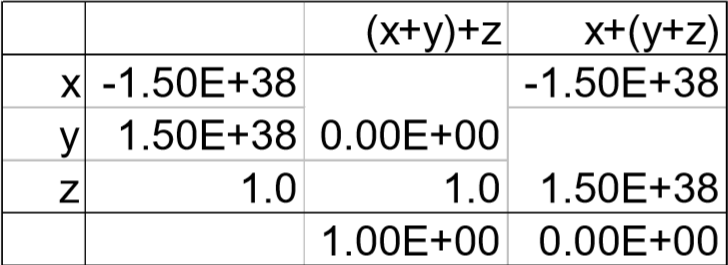
比如说向上面的一样,我们的单精度数能够表示的数字个数有限,当范围过大时,克表示的最小单位会超过1,那么这时将1加入,1无法准确计算,只能作为舍入依据