引言
自己看计组,顺便写个markdown玩玩,读的书叫《计算机组成与设计:硬件/软件接口》,作者目前大二,菜鸡一个,里面有部分观点完全出自于个人简介,如果出现了错误,还请各位大佬指正,关于指正可直接提交Issue,如长时间(3~4天)没有回复可以直接通过邮箱:wangsaiyu@cqu.edu.cn与我联系。
第一章 计算机概要与技术
1.1 引言
1.1.1计算应用的分类及其特性
从智能家电到手机再到超级计算机,他们都使用了一套通用的硬件技术,但是这些不同的应用有着不同的设计需求,并以不同的方式通过硬件实现。总的来说,计算机主要包括以下三种类型的应用:
- 个人计算机(PC):这是计算机最为人所知的应用方式,值得注意的是PC的出现只有短短的35年,但它推动了许多计算技术的革新。
- 服务器(server):服务器的制造技术和桌面计算机差不多,但是能够提供更强的计算、储存、I/O能力。通常情况下,发生故障时服务器的恢复代价远高于PC的恢复代价,因此服务器更加强调可靠性。
- 嵌入式计算机(embedded computer):这是数量最多的计算机,应用、性能领域非常广泛。嵌入式计算系统的设计目标是运行单一应用程序或者一组相关的应用程序,其设计目标是:运行单一应用程序或一组相关的应用程序,并且通常和硬件集成在一起以单一系统的方式一期交付给用户。(ps : 多bb一点,听去实习的学长说近几年来有很多硬件厂在做FPGA加速卷积运算代替GPU的work)
嵌入式应用通常对成本或工号又严格限制。以音乐播放器为例,处理器只需要尽量快速的执行有限的功能,除此外,减低成本和功耗是最大的目标。除此之外,由于故障会使使用者感到不适,亦有可能导致安全事故,因此嵌入式计算机对故障非常敏感。在面向消费者的嵌入式应用中,一般通过简单设计来获得可靠性——其重点在于尽可能地保持一项功能的正常运转。
结合我的个人经历来看,在今天基于深度学习的计算机视觉方案已经广泛应用于各个领域。在今天,人脸识别等基于深度学习的技术愈发发达,就连宿舍楼底下都撞上了人脸识别的闸机(再也不敢逃课睡觉了),但是在极端追求速度、准确度、性价比的场景中,深度学习方法仍然无法应用,以立体匹配问题为例,基于互信息熵和动态规划法的SGM方法能够满足在CPU上运行时的高准确率、实时性要求,与之对应的深度学习方法:GA-Net(注意,不是GAN)则需要6.5G显存、1080ti / Titan GPUs才能够跑得起,随着各种神仙算法的出现,网络越来越深需要的计算资源也越来越多,这里就反映出了当下深度学习方法在嵌入式系统的应用中存在的不足:
- 计算资源不足:在不提高成本的情况下很难满足深度学习方法的需求
- 计算速度不够:以智能车为例,为应对复杂的路况,周边信息的刷新率不能过低,但是现在深度学习领域的杰出方法的运行速度却不能得到保证,例如,在NVIDIA Titan X显卡环境下,Semi-Global Matching on the GPU可以达到886帧每秒,而深度学习方法仅能达到10.2帧每秒。
- 正确率相差不多:SGM和GCN的正确率相差不是很多,都可以满足实用的需求。
1.1.2 欢迎来到后PC时代
PMD:技术的持续进步给计算机硬件带来了革命性的变化,对整个信息技术工业产生了震动,随时代的发展,个人移动设备(Personal Mobile Device, PMD)正在逐步代替PC,当今的PMD可以是智能手机或平板电脑,而明天的PMD可能会包括电子眼镜等。
云计算:(cloud computing)替代了传统的服务器,它依赖于称为仓储规模计算机(Ware-house Scale Computer, WSC)的举行数据中心,一些公司可以租用其中一部分为PMD提供软件服务,而不用自己构建WSC,PMD与WSC是硬件工业的革命类似,通过云计算实现的软件即服务是软件工业的革命。
举个例子,在做一些项目的时候,我们需要用到很好的显卡,比如说上文中提到的GTX Titan,20,000¥起步,很显然,这种显卡不是我们能买的起的。但是我们可以租借云GPU服务器来满足我们的计算需求,ECS 的GPU 计算型,最便宜的 P4显卡1781.25 元/月,虽然价格也很贵,但是也是在我们能够支付得起的范围内满足我们的计算需求了。
1.2计算机系统机构中的8个伟大思想
面向摩尔定律的设计:摩尔定律指出单芯片上的集成度每18~24个月会翻一番
使用抽象简化设计:架构师和程序眼必须发明能够提高产量的技术,否则设计实践也会想资源规模一样按照摩尔定律增长,为解决这一问题使用的主要技术就是抽象来表达不同设计层级,在高层次中看不到低层次的细节,只能看到一个简化的模型。就像高级语言的出现一样,在使用numpy时,我们的代码经历了python->C->汇编->二进制码的过程。
加速大概率事件:相对于优化小概率事件,优化大概率事件的难度低,获得的收益高
通过并行提高性能:没什么好说的
通过流水线提高性能:我们在软件开发的时候也经常能听到相似的东西:高内聚,低耦合。说白了意思就是:把复杂的问题进行拆分,让每一个模块专精于某一个小的方向,这样就可以提高效率。在知乎上看到一个回答感觉很贴切,先贴上来,如图:

通过预测提高性能:在某些情况下,如果假定从误预测恢复执行代价不高并且预测准确率相对较高,则通过猜测的方式提前开始某些操作,要比等到确切知道这些操作应该启动时才开始要快
储存器层次:储存器的速度通常影响性能、储存器的容量限制了解题的规模、当今计算机系统中储存器的代价占了主要部分,人们希望储存器速度更快、容量更大、价格更便宜。设计师们发现可以通过储存器层次来解决这一问题,我们可以将其结构理解为一个金字塔,金字塔下方的储存单元有着容量大、价格便宜但计算速度较慢的特点,随着金字塔上层级的升高计算速度不断升高,但价格也愈发昂贵
通过冗余提高可靠性:任何一个物理器件都有可能失效,因此可以通过使用冗余部件的方式提高系统的可靠性
1.3 程序概念入门——两个抽象的例子
软件层次
计算机中的硬件只能执行极为低级的简单指令,从复杂的应用程序,到简单的指令需要经过几个软件层次来将复杂的高层次操作逐步解释或翻译成简单的计算机指令。下面的图中给出了这些软件的层次结构,外层是应用软件,中心是硬件,系统软件位于两者之间:

操作软件有很多种,其中两种对于今天的计算机来说是必需的:
- 操作系统:是用户程序和硬件之间的接口,为用户提供各种服务和监护功能,其最重要的作用是:
- 处理基本的**输入输出操作
- 分配外存和内存
- 为多个应用程序提供共享计算机资源的服务
- 编译程序:把用高级语言编写的程序翻译成硬件能执行的指令
从高级语言到硬件语言
第一代程序员是直接使用二进制数与计算机通信的,这是一项非常乏味的工作。所以他们很快发明了助记符,最初从助记符到二进制是通过手工翻译完成的,其过程过于繁琐,于是设计人员开发了汇编程序,可以将助记符形式的指令自动翻译成对应的二进制,但是汇编语言需要程序员写出计算机执行的每条指令,要求程序员像计算机一样思考,高级编程语言及其编译程序大大的提高了软件的生产力。
1.4 硬件概念入门
控制一台计算机的基础硬件都要完成相同的基本功能:输入数据、输出数据、处理数据、储存数据。计算机是由完成输入、输出、处理和储存数据的五个部件构成的,其中最关键的两个部件是:
- 输入设备(input device)如:麦克风、鼠标等
- 输出设备(output device)如:扬声器、显示器等
1.5功率趋势与功耗墙
\[CPU功耗 = \frac{1}{2}负载电容 * 工作电压^2 * 开关频率\]
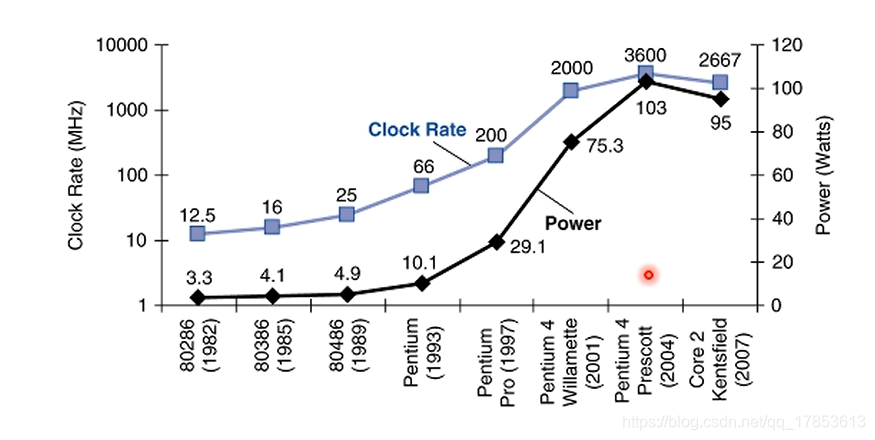
自1982年以来,时钟频率增长了一千倍不知,但功耗仅上升了30倍,这是因为能耗是电压平方的函数,能够通过降低电压来将大幅减少功耗,20多年来,电压从5V降到了1V,所以能耗仅上升了30倍。
从单处理器向多处理器的转变
从06年起,所有桌面和服务器公司都在单片位处理器中加入了多个处理器,以求更大的吞吐率,而不再继续追求降低单个程序运行在单个处理器上的响应时间。
那么为什么要才用多核的设计呢?

对于一个大核,为了达到两份的效率,需要付出4份的功耗 
对于一个小核,为了达到一份效率,只需要付出一份的功耗即可。小核达到大核\(\frac{1}{2}\)的效率,却只花费了\(\frac{1}{4}\)的功耗。 
将原有的大核拆分成四个小核,在并行情况良好的情况下,可以在功耗与大核相同的情况下,效率达到原来的2倍。 
可以看到,在红线处, 小核的效能和大核的一样,但是小核的功耗确实大核的一半,如果一个手机的内部同时有一个小核、一个大核,那么在处理日常事项时,使用小核,关闭大核。而在处理繁杂任务时使用大核,就可以极大的延长待机时间。
为什么大核的功耗是小核的四倍,效率却只有小核的两倍呢?
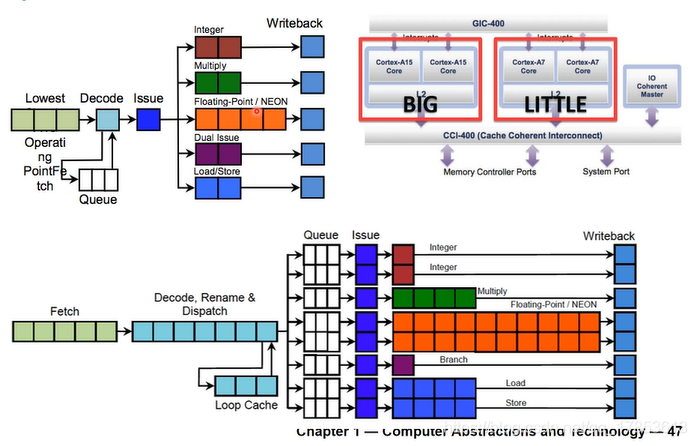
大核的功能单元多,流水线深度也较深,所以效率较高,但也正因如此,如果分支预测出错,需要进行回滚,那么浪费的能量也较多,相同情况下, 小核浪费掉的能量也少很多,所以小核可以具有更高的性能/功耗比。
1.6计算机性能的评价
影响计算机性能的因素
- 算法:算法决定了任务执行操作的数量
- 编程语言、编译器、指令集架构:影响了机器指令的数量
- 处理器和存储系统:决定了某一条语句的执行速度
- I/O系统:决定了执行I/O操作的时候需要的时间以及系统执行调用等操作时需要的时间
计算机性能评价指标——响应时间与吞吐率
- 响应时间:给定一任务,需要的执行时间
- 吞吐率:表示单位时间内完成的任务数量
定义计算机性能公式:
\[P_X = 性能_x = \frac{1}{响应时间}\]
要对比两台计算机的性能可以对比他们的相对性能:
\[\frac{性能_x}{性能_y} = \frac{响应时间_y}{响应时间_x}\]
度量任务执行的时间
- 响应时间(Elapsed time):也叫墙上时钟时间(wall clock time)表示完成任务所需要的总时间,受完成任务的处理时间、IO时间、操作系统消耗的时间、不同任务之间调度的时间等等,这种度量方法并不准确。
- CPU时间(CPU time):只表示在CPU上面的时间刨去了I/O、或运行其他程序的时间等。
计算CPU时间的方法,相关变量:
- 时钟周期、时钟频率:\[时钟周期 = \frac{1}{时钟频率}\]
有公式:
\[CPU时间 = CPU时钟数 * 时钟周期 = \frac{时钟数}{时钟频率}\]
由此可见,想要降低CPU时间,需要升高时钟频率,同时减小时钟数。
指令条数(Instruction Count) 与 CPI
\[机器周期数 = 指令条数 * 每条指令需要的机器周期数\]
\[CPU时间 = 指令条数 * CPI * 时钟周期 = \frac{指令条数 * CPI}{时钟频率}\]
- 程序的指令条数:取决于算法、编程语言、编译器、指令集架构
- CPI:由CPU性能决定,不同的指令有不同的CPI,加法、除法等指令CPI不同
\[时钟周期 = \Sigma^{n}_{i=1} (CPI_i * 指令条数_i)\]
\[CPI_i = \frac{时钟周期}{指令条数} = \Sigma_{i=1}^{n}CPI *\frac{指令条数_i}{总指令条数}\]
关于性能的总结:\[\frac{秒数}{程序} = \frac{指令数}{程序}\frac{时钟周期数}{指令数}\frac{秒数}{时钟周期数}\] 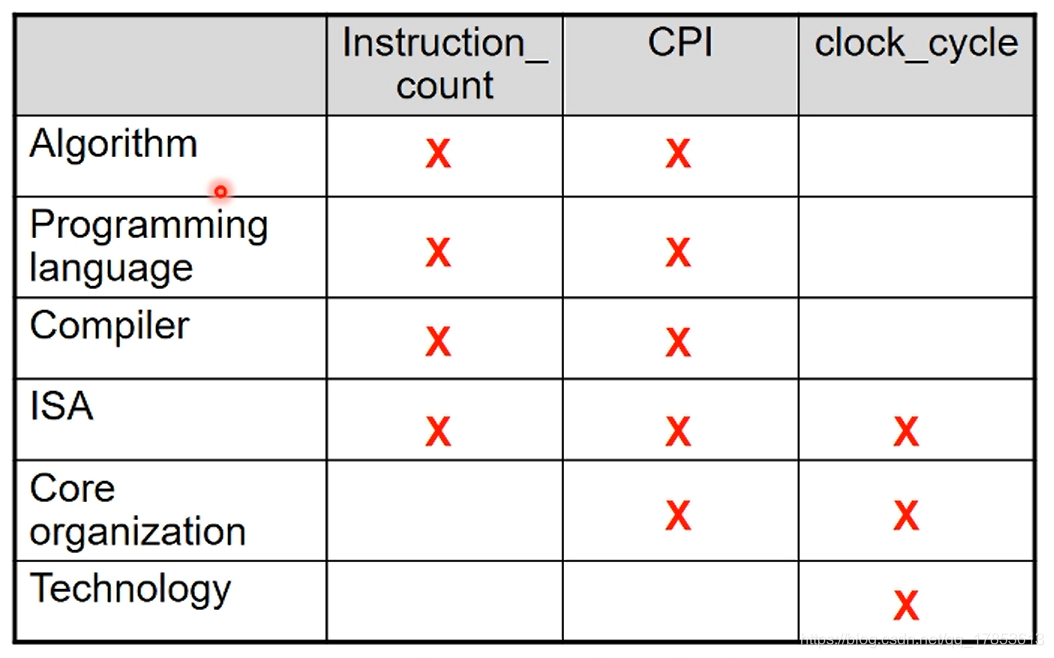
从图中我们可以看出不同的因素对计算机性能的影响,可以看出:
- 软件层主要通过影响指令数和CPI来影响计算机性能
- 硬件层主要通过影响时钟周期和CPI来影响计算机性能
对于1982年的程序员来说,写好一个程序之后什么都不用干,到了今天,他的程序性能会比当年高一千倍不止,这是因为计算机硬件的不断发展,但是今天,计算机不再追求降低单个程序运行在单个处理器上的响应时间,也就是说我们想要改善计算机运行速度,应当着重从软件层次入手,优化算法、优化编译程序、指令集架构等。
综合评价CPU性能方法——SPEC CPU
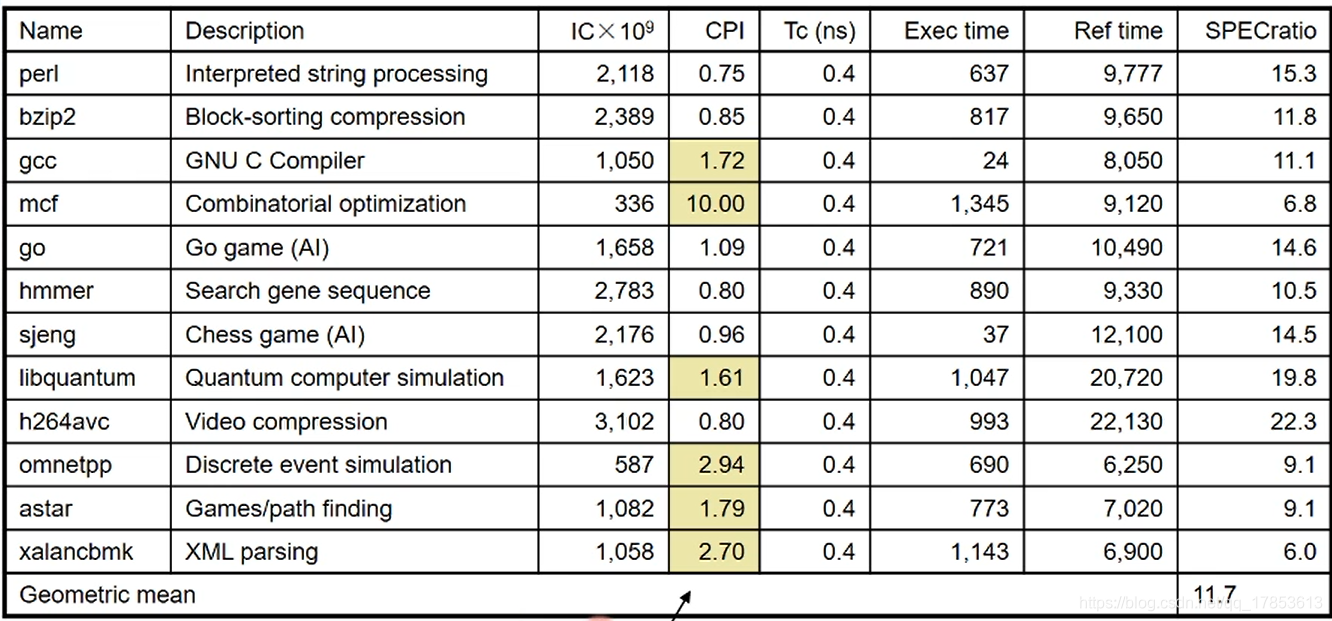
在这个测试表中,对CPU在固定环境下,进行了不同应用场景的测试,如字符串处理、围棋游戏、视频压缩等,并且记录下来了完成任务的时间:\(Exce\_time\),将其与\(Ref\_time\)进行对比,得到了\(SPECratio\)有公式:\(SPECratio = \frac{Ref\_time}{Exce\_time}\)
总体性能评价使用了几何平均公式:
\[Geometric\_mean = \sqrt[n]{\Pi_{i=1}^n 执行时间比_i}\]
1.7 关于计算机性能改进的指标
阿姆达尔定理
\[改进后的执行时间 = \frac{受改进影响的执行时间}{改进量} + 不受影响的执行时间\]
如果乘法运算占总负载的80%,那么无论怎样改进算法,也无法让整体性能提高5倍。这是因为仅提升乘法运算速度,不会影响其他的执行时间。
同时阿姆达尔定理也揭示了:在改进计算机的时候,应当优先改进
用MIPS度量计算机性能(已过时)
MIPS:执行 MIPS百万条指令/秒
\[MIPS = \frac{指令数}{执行时间 * 10^6}\]
可以看出在今天,MIPS已经不能正确的的描述CPU的运算能力,这是因为今天的计算机指令较为复杂,不同指令之间的CPI相差较大,所以不能用指令数来简单的代表总任务量。
1.8 性能评价——功耗问题
现如今,计算资源消耗的能量占了全世界能耗的2%, 如今能耗问题成为了一个受关注的点。
SPEC功耗评价
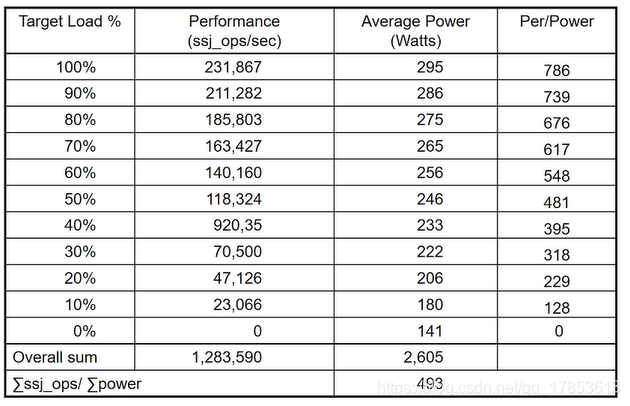
SPEC采用单个的数字来进行归纳,称为\(overall \ ssj\_ops\ per\ watt\)
\[overall\ ssj\_ops\ per\ watt = \frac{\Sigma_{i=0}^{10}ssj\_ops_i}{\Sigma_{i=0}^{10}{power_i}}\]
值得注意的是,10%负载并不代表10%消耗,可以发现,负载越高功耗比越高。